Continuing with my transition from network folders to a Rmarkdown blog system, I found a presentation I gave on few best practices for the construction of well models. After three years of building wells and network models, I came up with this list of recommended practices. It is unique in the sense that it took lessons learned by tackling the continuous well optimization process using Data Science.
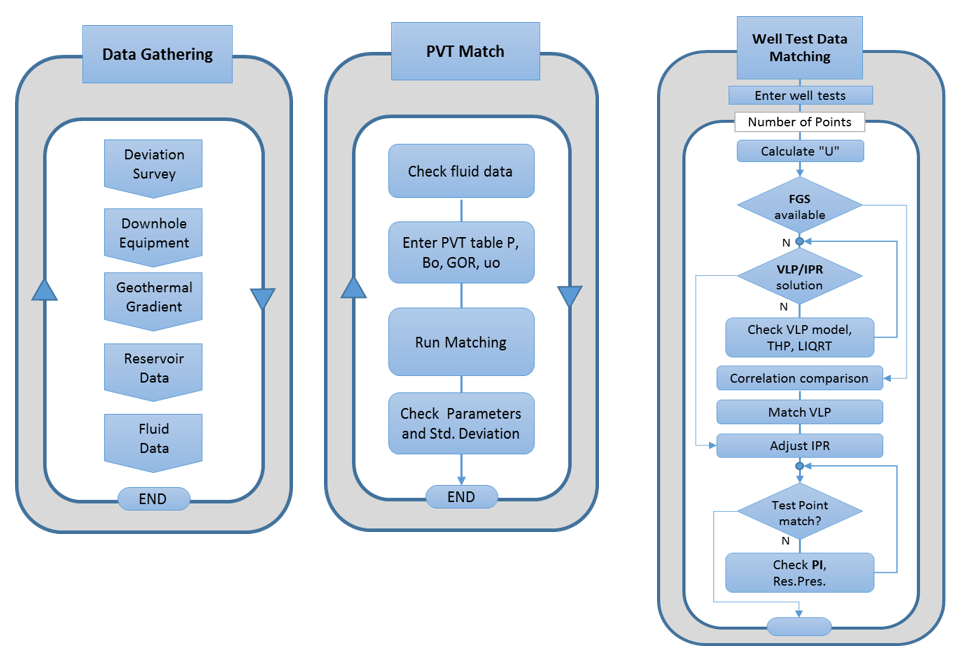
The previous article Scripts for Well Modeling and Batch Automation is part of the execution of well modeling which is just a component of the whole process. One of the most important aspects of well modeling is gathering, qualifying and validating the data. This is what this article is about.
I have published a set of slides that goes through some of well subsystems that require data collection before entering them into a model. Here is the slide set:
What I cover in these slides:
- Inventory of the well data
- Pressure tests
- Fluid data
- Well schematics and surveys
- PVT data
- Zones and layers data
- Activation matrix for well status
- Well and string identification
- When you should stop
- Folders and files
- Modeling software
The slides were generated using Latex Beamer and Rmarkdown from RStudio.
This is the link to the Github repository if you are interested. The link to the slide set points to SlideShare.
Soon, as I progress with the transition of the material that I collected over the years on data science for petroleum engineering, I will be releasing something more dynamic that can be generated directly from R.
Note
The slides are also available in SpeakeeDeck: